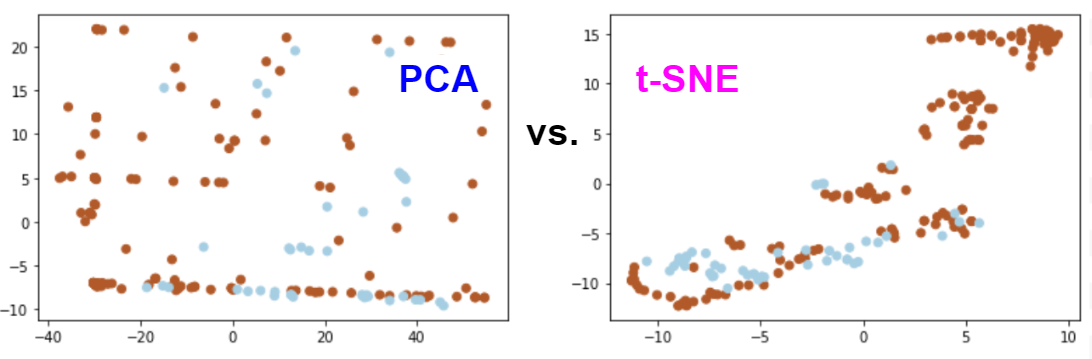
In Part 3, we tried to apply the feature scaling and dimensionality reduction techniques to the dataset with phishing and benign URLs. As a result, we were able to clearly see the distribution of URLs between two classes based on four attributes: registrar, country, lifetime, and protocol.
But what if we don’t have labels (phishing and benign) for the Internet links in the beginning. Will ML still work to detect phishing attacks? In this case, we may come to unsupervised learning, in particular, clustering. Clustering enables grouping objects of unknown classes according to common features so that we do not need labeled data for a training set.